|
Position: Strong Consumer Protection is an Inalienable Defense for AI Safety in the United States
International Conference on Machine Learning (ICML)
2025
|
|
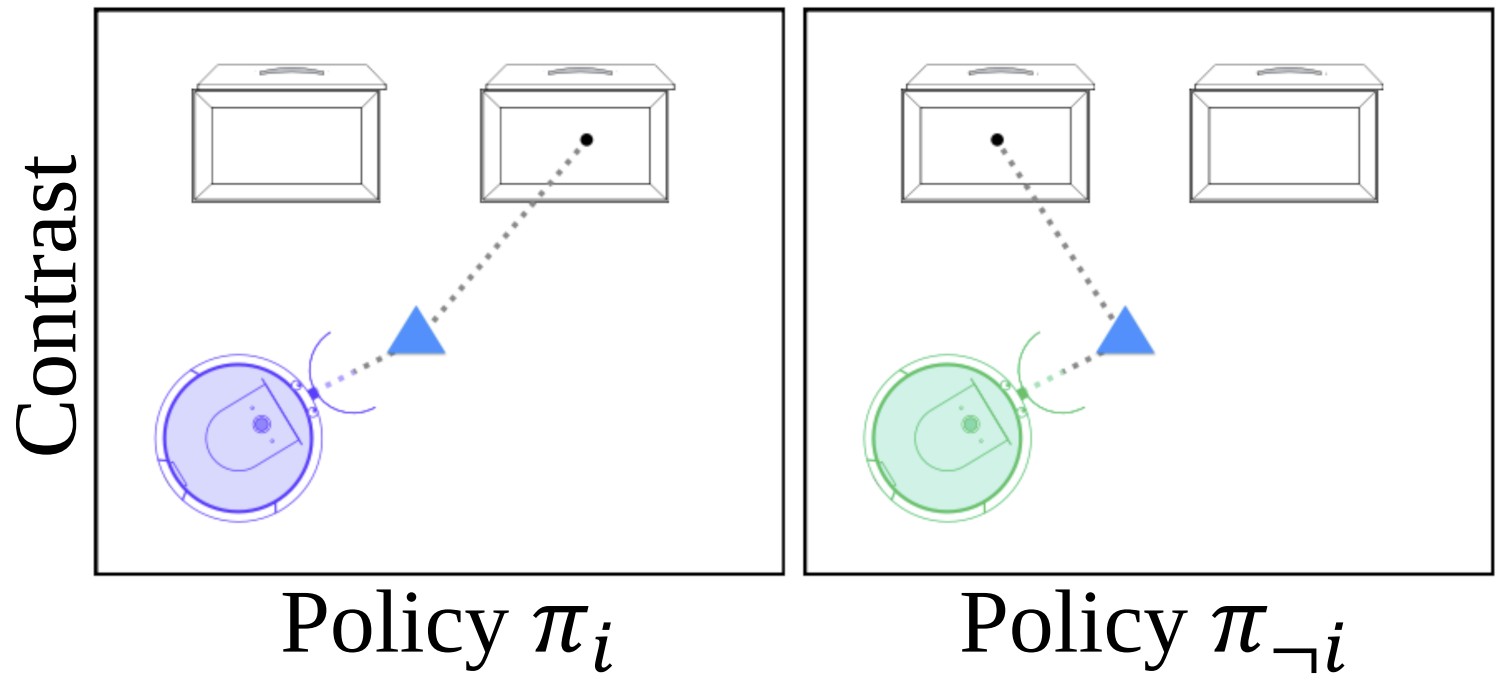
Towards Improving Reward Design in RL: A Reward Alignment Metric for RL Practitioners
Reinforcement Learning Conference (RLC)
2025
|
|
Goals vs. Rewards: Towards a Comparative Study of Objective Specification Mechanisms
Reinforcement Learning Conference (RLC)
2025
|
|
Models of Human Preference for Learning Reward Functions
Transactions on Machine Learning Research (TMLR)
2024
|
|
Learning Optimal Advantage from Preferences and Mistaking it for Reward
AAAI Conference on Artificial Intelligence
2024
|
|
Quality-Diversity Generative Sampling for Learning with Synthetic Data
AAAI Conference on Artificial Intelligence
2024
|
|
The Perils of Trial-and-Error Reward Design: Misdesign through Overfitting and Invalid Task Specifications
AAAI Conference on Artificial Intelligence
2023
|
|
Extended Abstract: Graduate Student Descent Considered Harmful? A Proposal for Studying Overfitting in Reward Functions
Multidisciplinary Conference on Reinforcement Learning and Decision Making
2022
|
|
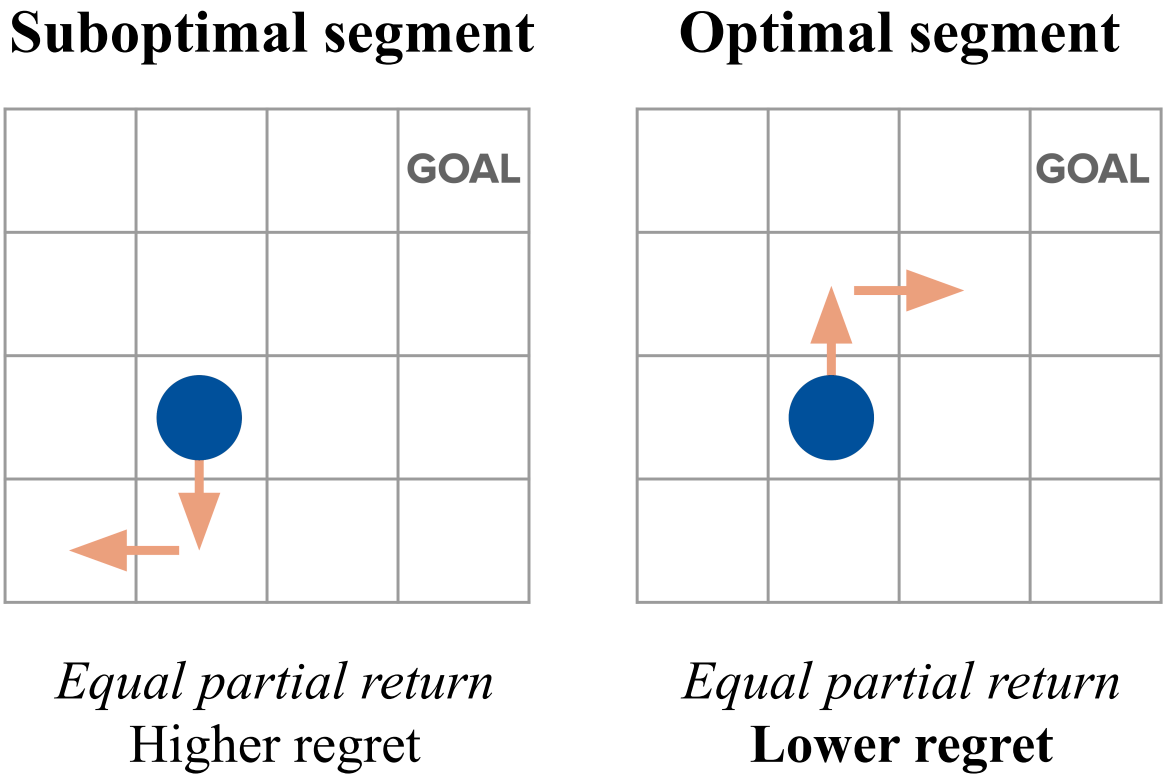
Spotlight, Extended Abstract: Partial Return Poorly Explains Human Preferences
Multidisciplinary Conference on Reinforcement Learning and Decision Making
2022
|
|
Revisiting Human-Robot Teaching and Learning Through the Lens of Human Concept Learning Theory
ACM/IEEE International Conference on Human-Robot Interaction (HRI)
2022
|
|
Do Feature Attribution Methods Correctly Attribute Features?
AAAI Conference on Artificial Intelligence
2022
|
|
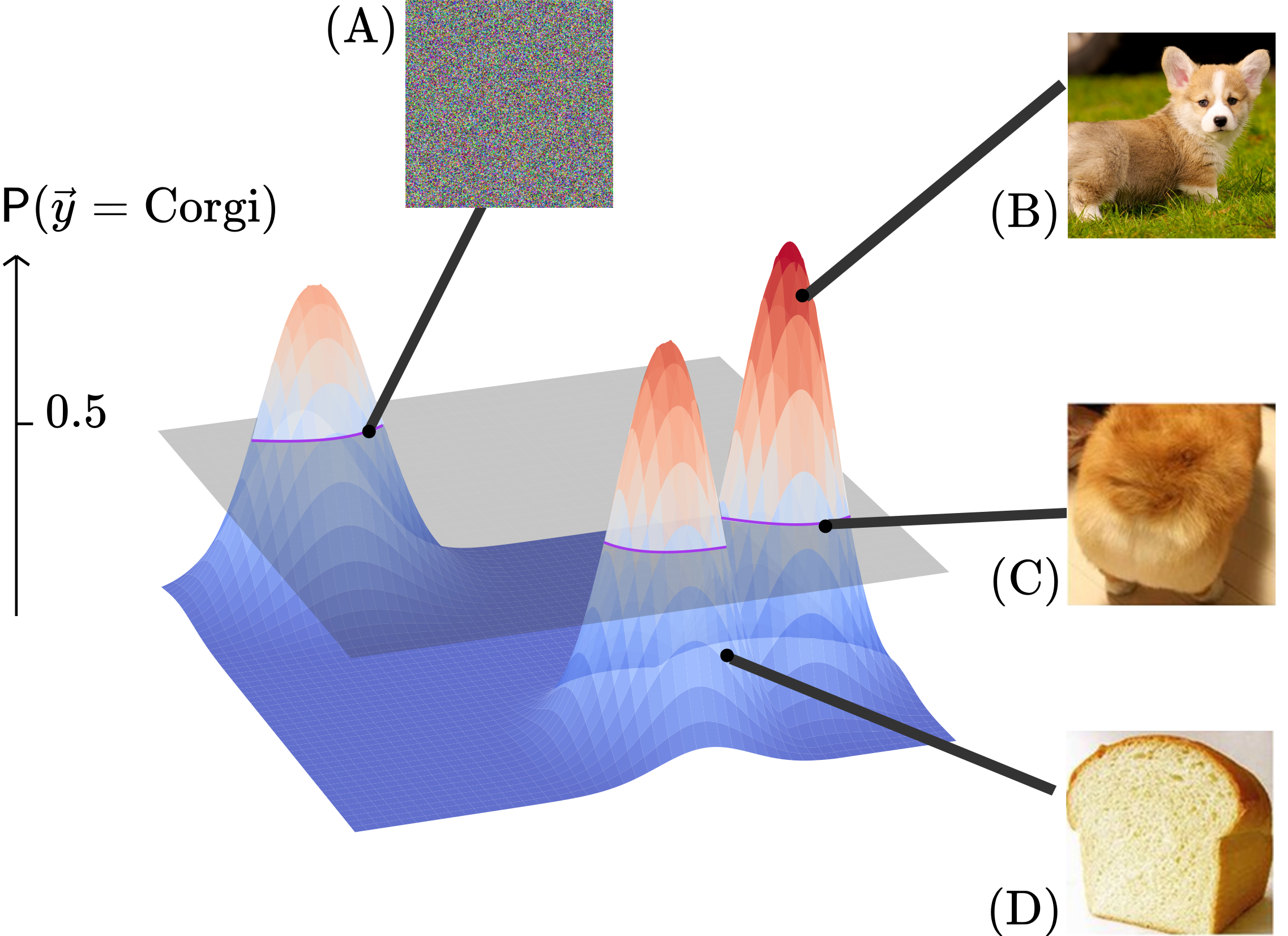
Bayes-TrEx: A Bayesian Sampling Approach to Model Transparency by Example
AAAI Conference on Artificial Intelligence
2021
|
|
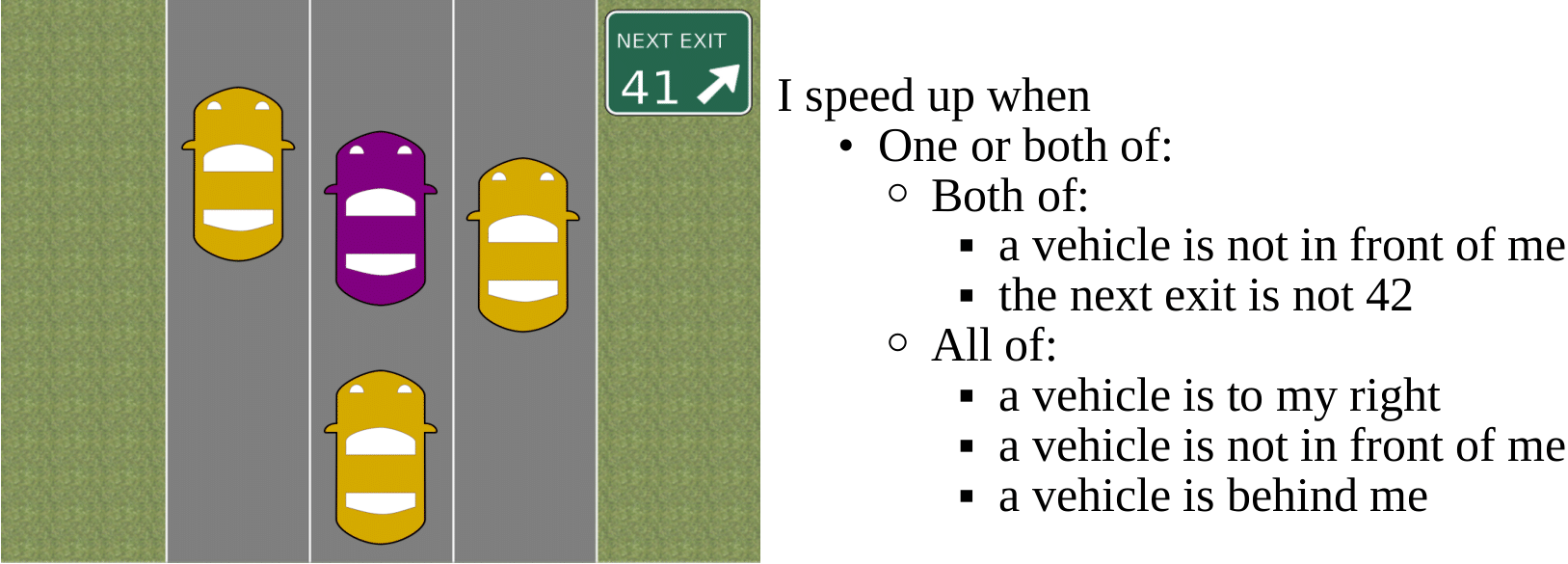
RoCUS: Robot Controller Understanding via Sampling
Conference on Robot Learning (CoRL)
2021
|
|
Machine Learning Practice Outside Big Tech: How Resource Constraints Challenge Responsible Development
AAAI/ACM Conference on Artificial Intelligence, Ethics, and Society (AIES)
2021
|
|
Evaluating the Interpretability of the Knowledge Compilation Map: Communicating Logical Statements Effectively
International Joint Conference on AI (IJCAI)
2019
|
|
Piggybacking Robots: Human-robot Overtrust in University Dormitory Security
ACM/IEEE International Conference on Human-Robot Interaction (HRI)
2017
|