|
AAAI 2023
|
||
|
The Perils of Trial-and-Error Reward Design: Misdesign through
Overfitting and Invalid Task Specifications
|
| Serena Booth1, 2, 3 | W. Bradley Knox1, 2, 5 | Julie Shah3 | Scott Niekum2, 4 | Peter Stone2, 6 | Alessandro Allievi1, 2 |
|
1Bosch
|
||
|
2University of Texas at Austin
|
||
|
3MIT Computer Science and Artificial Intelligence
Laboratory
|
||
|
4University of Massachusetts Amherst
|
||
|
5Google Research
|
||
|
6Sony AI
|
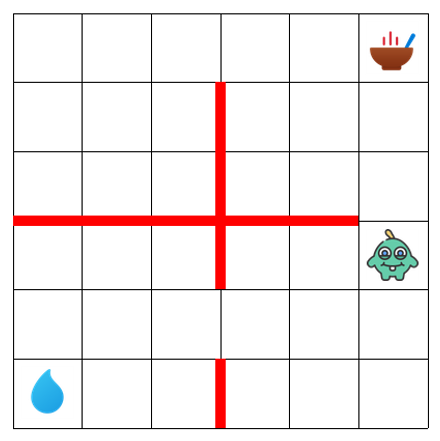
We use the Hungry Thirsty domain to study the practice of reward design empirically through
a combination of computational studies and controlled-observation user studies.
Hungry Thirsty is a simple gridworld! In this domain, food and water are located in random corners. The agent's objective is to eat as much as possible. But, of course there's a catch: the agent can only eat when it is not thirsty. On each timestep, there's a 10% probability the agent becomes thirsty. This domain has significant richness for studying reward design. The sparse reward function (1 when the agent is not hungry and 0 otherwise) is a perfectly good reward function: we found this reward function supports learning the optimal policy with Q-learning, DDQN, PPO, or A2C. However, unsafely shaped reward functions—i.e., those which reward learning to drink as a subgoal—can support faster learning. |
| Abstract |
|
In reinforcement learning (RL), a reward function that aligns exactly with a task's true
performance metric is often sparse. For example, a true task metric might encode a reward of 1
upon success and 0 otherwise. These sparse task metrics can be hard to learn from, so in
practice they are often replaced with alternative dense reward functions. These dense reward
functions are typically designed by experts through an ad hoc process of trial and error. In
this process, experts manually search for a reward function that improves performance with
respect to the task metric while also enabling an RL algorithm to learn faster. One question
this process raises is whether the same reward function is optimal for all algorithms, or, put
differently, whether the reward function can be overfit to a particular algorithm. In this
paper, we study the consequences of this wide yet unexamined practice of trial-and-error reward
design. We first conduct computational experiments that confirm that reward functions can be
overfit to learning algorithms and their hyperparameters. To broadly examine ad hoc reward
design, we also conduct a controlled observation study which emulates expert practitioners'
typical reward design experiences. Here, we similarly find evidence of reward function
overfitting. We also find that experts' typical approach to reward design---of adopting a myopic
strategy and weighing the relative goodness of each state-action pair---leads to misdesign
through invalid task specifications, since RL algorithms use cumulative reward rather than
rewards for individual state-action pairs as an optimization target.
Code, data: https://github.com/serenabooth/reward-design-perils.
|
| Overview Presentation (AAAI 2023 Spotlight) |
|
@inproceedings{booth23perils,
|